ASC+MEME is a fast motif discovery tool that is 10,000 times faster than MEME while preserving the same accuracy.
In particular, on a test with about 10,000 protein sequences, ASC+MEME reduces the running time of MEME from weeks to a few minutes with even better accuracy (check the comparison here). On another test with millions of protein sequences, ASC+MEME can also finish within hours.
News:
07/2017: We have recently developed a new motif discovery tool, DeepMotif, that acheives even better performance than ASC+MEME. It's 10-100 times faster and doesn't rely on MEME. DeepMotif can run in near real time. A performance comparison between DeepMotif and MEME is avaliable here. For more information and licensing, please contact Dr. Honglei Liu (liuhonglei@gmail.com).
06/2017: ASC was licensed to SerImmune Inc. funded by NIH, illumina, Merck, etc. to find motifs from massive protein sequences generated by modern sequencing techniques.
Introduction
Traditional motif finding algorithms such as MEME cannot scale well w.r.t. number of sequences and size of alphabet set. Especially for protein sequences, existing tools either work only in a small scale of several hundred sequences or have to trade accuracy for efficiency. We introduce an anchor-based clustering (ASC) algorithm that can significantly improve the scalability of all the existing motif finding algorithms without losing accuracy at all. ASC+MEME is created by combining ASC and MEME.
ASC works by intelligently dividing a sequence dataset into multiple smaller clusters so that sequences sharing the same motif will be located into the same cluster. Then an existing motif finding algorithm can be applied to each individual cluster to generate motifs. In the end, the results from multiple clusters are merged together as final output. Experimental results show that our approach is generic and orders of magnitude faster than traditional motif finding algorithms. It can discover motifs from protein sequences in the scale that no existing algorithm can handle.
Architecture
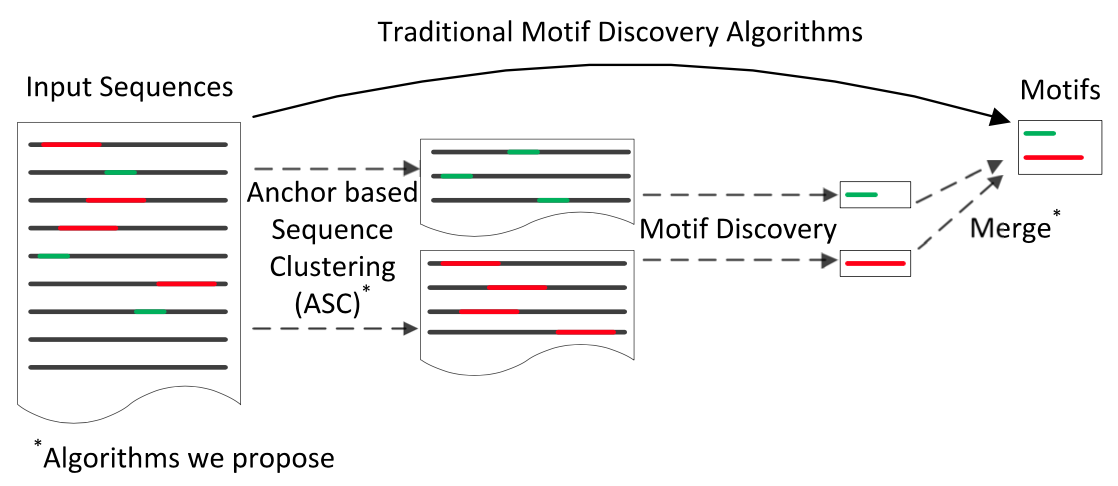
Rather than developing another motif finding algorithm to outperform existing ones, we propose a new strategy, that is pre-processing sequences with clustering, to divide the data into multiple small clusters and run existing motif finding algorithms on each cluster. The Figure below shows a sketch of the clustering and motif discovery pipeline. Sequences are first grouped into clusters before a motif finding algorithm is applied. Motifs discovered from each cluster are merged together and delivered to users.
In the ASC algorithm we proposed, each sequence is decomposed into a set of anchors which are similar to gapped q-grams, but with variable shapes. Sequences are clustered based on anchors they contain to avoid pairwise sequence comparisons. In particular, these anchors are not randomly selected. They are from the most significant ones in the dataset and then iteratively refined. Afterwards, a set of sequences are sampled from each cluster and provided to an existing algorithm to find motifs
For more details about ASC, please refer to the documents